Table des matières
Récemment, j'ai dû déployer une solution permettant de préparer rapidement les nouvelles machines entrantes dans le parc informatique. La solution retenue et installée est Clonezilla Server Édition. Ce billet se propose de vous exposer les différentes phases de ce projet : la réalisation d'un cahier des charges, le choix de la solution ainsi que son installation et son utilisation.
Situation initiale
Chaque année, 30 % à 40 % du parc informatique est renouvelé, soit environ une cinquantaine de machines. Nous devons donc préparer les nouvelles machines. Cette préparation est longue puisqu'elle comporte l'installation et la personnalisation (ex. : désactivation des services inutiles) de Windows, l'installation des pilotes de périphériques, l'installation des logiciels qui sont communs à tous les utilisateurs.
Par chance, les machines reçues la même année sont homogènes d'un point de vue de leur configuration matérielle. Il n'y a qu'à de rares occasions que les machines sont hétérogènes. Par exemple : une année, nous avions deux modèles de machine.
De ce fait, nous utilisons le principe des images disque : nous installons et personnalisons Windows sur une seule machine, nous installons les pilotes de périphériques associés ainsi que les logiciels. Puis nous réalisons une image disque que nous restaurons sur toutes les autres machines. Le logiciel de clonage est imposé : il s'agit de True Image d'Acronis.
Comme toutes les machines sont dorénavant livrées en une seule vague, nous avons décidé, après réflexion, d'automatiser le processus de restauration de l'image disque sur toutes les machines, via le réseau.
D'autres solutions que le clonage en réseau peuvent correspondre à vos besoins, notamment si vos machines ne sont pas homogènes.
Il existe des produits logiciels qui permettent le déploiement de Windows et/ou de distribution GNU/Linux et de logiciels. À titre d'exemple, nous pouvons citer Microsoft Windows Deployment Services, DRBL ou bien encore WPKG. Néanmoins ces produits ne nous conviennent pas pour deux raisons. La première : le déploiement se déroule en plusieurs phases : il faut déployer Windows, puis les pilotes de périphériques puis les logiciels. En admettant que cela soit possible (je pense au déploiement des pilotes), cela reste fastidieux. La deuxième : nous sommes déjà habitués à l'utilisation des images disques. Il s'agit donc d'une évolution de notre mode de fonctionnement plus qu'une révolution.
Nous avions aussi la possibilité de transformer les machines clientes en des clients légers. Malgré les avantages que ce modèle propose (administration centralisée, évolution limitée à l'acquisition d'un nouveau serveur, sécurité, etc.), il impose de réfléchir à de nouvelles problématiques (ex. : tolérance aux pannes du serveur). Nous n'avons pas retenu ce choix pour l'instant mais il pourrait être une évolution du SI dans un futur proche.
Nous avons décidé de ne pas configurer automatiquement les paramètres réseau après le clonage. Néanmoins, si cela vous intéresse, les outils NewSID ou SysPrep ou même des scripts batch en utilisant la commande netsh sont faits pour vous.
Concernant le BIOS, il est possible de configurer le BIOS des machines à distance mais cela est réservé, d'après ce que je sais, aux machines professionnelles. Intel Active Management Technology permet ce genre de choses.
Cahier des charges
Nous cherchons donc une solution de clonage en réseau. Les principaux critères de sélection de la solution seront :
- Simplicité d'utilisation (l'installation peut être compliquée, mais l'utilisation au quotidien doit être simple (voir simpliste) puisqu'elle sera réalisée par des personnes moins compétentes).
- Fiabilité.
- Gratuité.
- En français si possible.
- La solution doit utiliser des composants logiciels éprouvés et doit être intégralement disponible sous une licence libre (GNU GPL, BSD, MIT, …).
Choix de la solution
Attention : la solution retenue l'est par rapport à nos besoins. Selon vos besoins, vous ne retiendrez peut-être pas la même solution.
Les solutions trouvées mais qui ne correspondent pas à nos besoins peuvent être rangées dans 4 catégories. Les logiciels présents dans ces catégories sont des exemples et la liste des logiciels présentés n'est pas exhaustive (ex. : nous pouvons rajouter UDPCast dans la catégorie des logiciels difficiles à prendre en main).
Les logiciels propriétaires et/ou payants
Exemples : Symantec Norton Ghost Solution Suite, Acronis Backup & Recovery 10 Advanced Server ...
Les logiciels obsolètes
Partimage serveur : utilitaire GNU/Linux sous licence libre (GNU GPL) permettant la création et la restauration d'image disque depuis un serveur. Il permet de copier uniquement les données utiles du système de fichier et d'ignorer, par exemple, les espaces vides. Néanmoins, le support du NTFS, système de fichiers propre aux systèmes d'exploitation de Microsoft depuis Windows XP est expérimental, ce qui le disqualifie au vu des besoins en terme de stabilité. De plus, le logiciel n'est plus maintenu. À titre d'exemple, nous pouvons citer le fait que le système de fichiers ext4, présent dans les distributions GNU/Linux depuis fin 2008 n'est toujours pas supporté par Partimage.
Les logiciels difficiles à prendre en main
G4U : utilitaire sous licence libre (BSD) permettant la création d'images disque bit par bit ce qui lui permet le support de tous les systèmes de fichiers. Mais, d'une part, il copie les espaces vides des disques durs, ce qui accroît la taille des images inutilement ainsi que la bande passante réseau et le temps de clonage nécessaires. D'autre part, l'utilisation de cet outil dans un contexte réseau s'avère difficile à mettre en place et à maintenir.
Les logiciels trop complets
OSCAR : l’Outil Système Complet d’Assistance Réseau est un logiciel sous licence libre (GNU GPL) qui permet de sauvegarder et de restaurer facilement un poste ou encore de cloner un ensemble de postes identiques. Cette solution est intéressante puisqu'elle permet de transformer chaque machine en serveur. En effet, chaque machine stocke OSCAR ainsi que l'image de son disque sur son propre disque dur. Ainsi, après toute modification sur un poste, on peut recréer l'image et la déployer sur tout le réseau. Autre fonctionnalité intéressante : il suffit de démarrer un poste sur un CD d'assistance pour restaurer automatiquement l'image disque en cas de problème. Des fonctionnalités qui sont intéressantes mais qui dépassent le cadre de nos besoins. Or, plus de fonctionnalités = plus de bugs potentiellement possibles.
La solution retenue
De ce fait, une dernière solution correspond à nos besoins : il s'agit de Clonezilla Server Édition.
Il s'agit de la version serveur du logiciel de clonage libre Clonezilla Live. Disponible sous une licence libre (GNU GPL) et en français, Clonezilla Server Édition repose sur des composants logiciels éprouvés : DRBL, Partclone, UDPCast, ... Une interface graphique est disponible, ce qui le rend simple d'utilisation au quotidien après, cependant, une installation qui peut paraître laborieuse. Il tourne sur les systèmes GNU/Linux les plus populaires (Debian, Fedora, CentOS, etc.).
Un mot de réseau
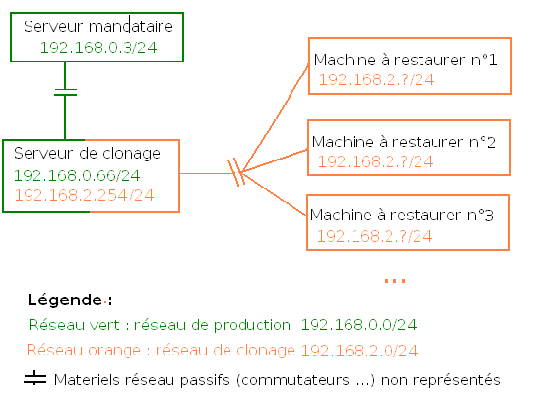
Voici le schéma réseau de notre installation de Clonezilla Server Édition :
Comme l'illustre le schéma ci-dessus, les machines qui seront clonées seront isolées, au niveau physique et logique, sur un réseau indépendant. Cela permet d'éviter qu'un ordinateur du réseau "normal"/de production dont le BIOS est mal configuré ne soit sauvegardé/restauré par erreur. Le serveur de clonage est tout de même connecté au réseau afin de pouvoir être mis à jour via internet dans l'optique de supporter un ensemble de configurations matérielles toujours plus important. Néanmoins, le serveur ne sert pas de passerelle : les machines à sauvegarder/restaurer ne peuvent pas communiquer avec les machines du réseau "normal"/de production.
Note : il n'est pas nécessaire d'avoir deux cartes réseau. En effet, une seule carte réseau peut-être utilisée mais l'utilisation du serveur sera moins simple. Pour mettre le serveur à jour, il faut brancher la carte réseau sur le réseau "normal"/de production, faire la configuration réseau (ipconfig+route ou /etc/network/interfaces), effectuer la mise à jour puis brancher la carte réseau sur le réseau de clonage puis refaire la configuration réseau à nouveau.
Dans la suite de ce tutoriel, je considérerai que votre serveur possède deux cartes réseau. Je considérerai également que votre réseau de production n'utilise pas le protocole DHCP pour réaliser la configuration réseau de manière automatique des machines. Enfin, je considérerai que la connexion internet est accessible via un serveur mandataire (proxy) uniquement et que ce serveur se trouve sur le réseau de production. Si cela n'est pas le cas, vous devrez adapter ce tutoriel à votre installation.
Installation de Clonezilla Server Édition
Dans un premier temps, nous allons installer le système d'exploitation GNU/Linux Debian puis le configurer. Ensuite, nous installerons Clonezilla Server Édition et nous le configurerons.
Enfin, une étape facultative permettra la création de raccourcis dans le menu des applications et sur le bureau afin de rendre l'utilisation de Clonezilla Server Édition plus agréable.
Installation du système GNU/Linux Debian Squeeze
Note : le système GNU/ Linux Debian a été retenu pour son large support matériel, sa philosophie du Libre et sa stabilité (selon les dépôts utilisés, évidemment). Néanmoins, un autre système GNU/Linux peut-être utilisé.
-
Démarrez l'ordinateur et mettez le CD dans le lecteur. Le BIOS étant configuré, vous n'avez rien d'autre à faire pour démarrer sur le CD.
-
Un menu apparaît. L'option que nous souhaitons, « Install » est déjà sélectionnée. Validez avec la touche « Entrée » de votre clavier. À chaque fois que nous écrirons « Validez », comprenez que vous devez appuyer sur la touche « Entrée ».

-
Sélectionnez votre langue (« French ») avec les touches fléchées de votre clavier. Validez.
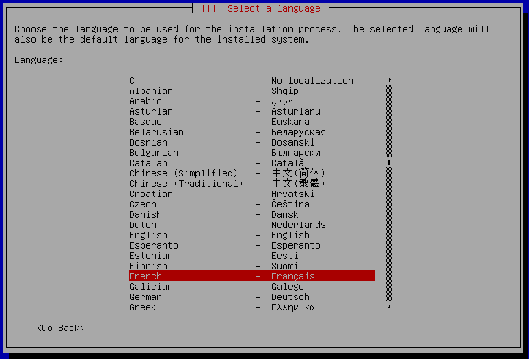
-
Sélectionnez votre situation géographique (= votre pays). La France est déjà sélectionnée donc validez.
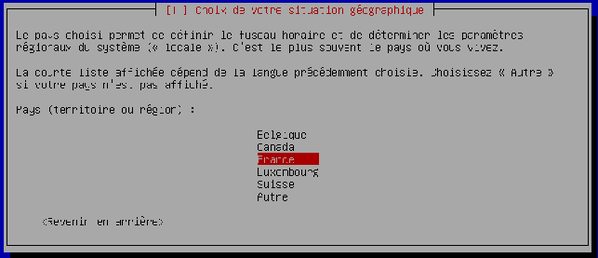
-
Choisissez la disposition des touches de votre clavier. « Français (fr-lation9) » est déjà sélectionnée donc validez.
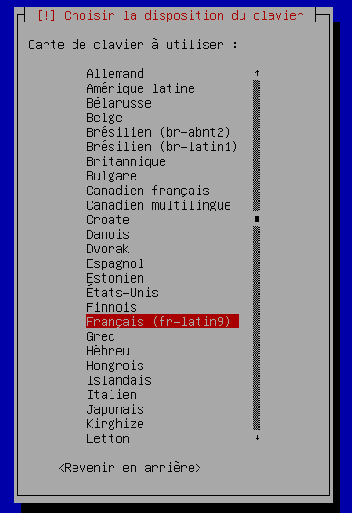
-
Le système va charger des composants supplémentaires depuis le CD. Laissez-le faire.
-
Lorsque le système vous demande votre carte réseau principale, validez simplement.
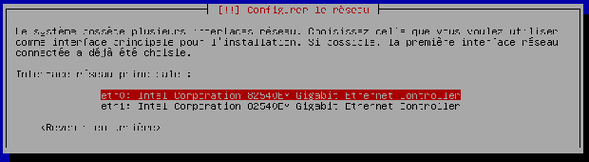
-
Nos réseaux ne disposent pas du protocole DHCP. La tentative de configuration automatique va donc échouer. Vous pouvez attendre ou appuyer sur la touche « Entrée » pour l'annuler directement.
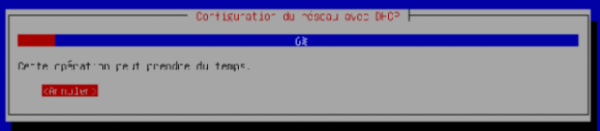
-
Le système vous demande ce que vous souhaitez faire compte tenu de l’échec de la configuration automatique du réseau. Choisissez de « Ne pas configurer le réseau maintenant » et validez.
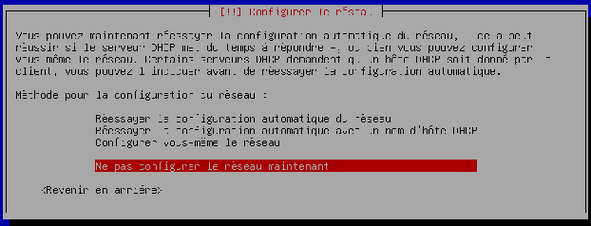
-
Le système vous demande quel nom vous souhaitez donner à la machine. Nous avons choisi « clone-srv » mais peu importe. Tapez le nom et validez.
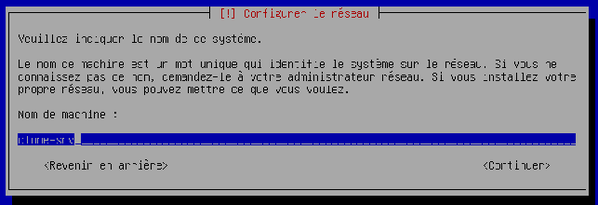
-
L'assistant vous demande le mot de passe du super-utilisateur (= root). Choisissez-en un et validez.
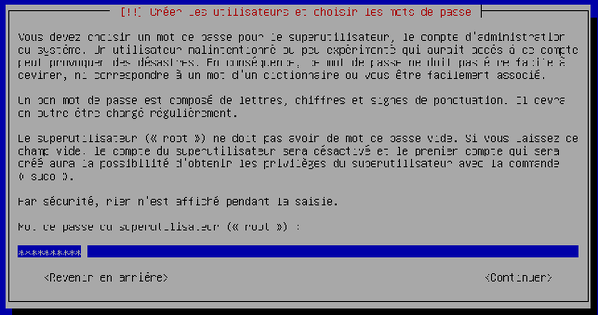
-
L'assistant vous demande de confirmer le mot de passe du super-utilisateur. Saisissez-le et validez.
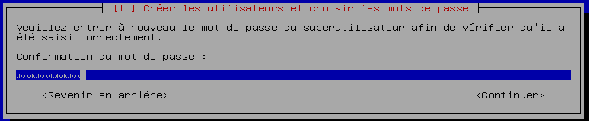
-
On vous demande à présent le nom complet de l'utilisateur afin de créer un compte utilisateur « simple » (sans droits avancés). Choisissez-en un, saisissez-le et validez.
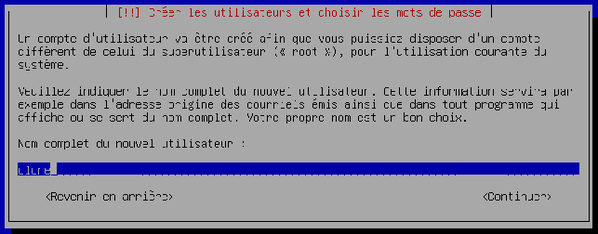
-
Laissez l'identifiant proposé et validez.
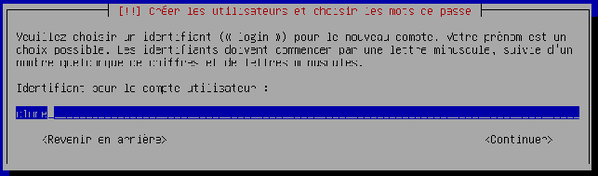
-
Saisissez le mot de passe de l'utilisateur et validez.
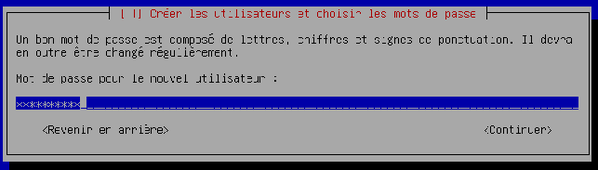
-
Confirmez le mot de passe de l'utilisateur et validez.
-
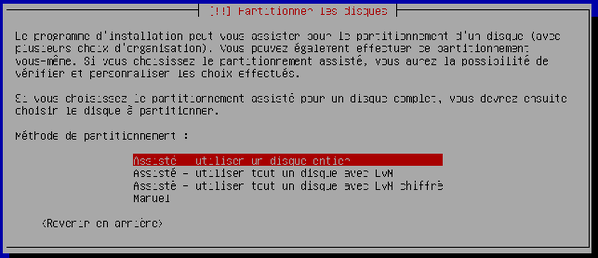
Nous passons maintenant à la phase de partitionnement du disque dur. Laissez l'assistant vous aider à partitionner l'intégralité du disque dur (« Assisté – utiliser un disque entier ») en validant simplement.
-
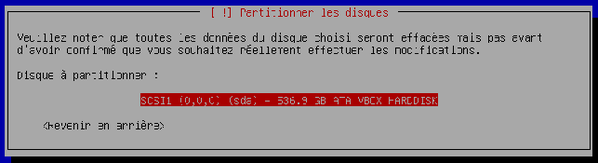
L'assistant vous demande quel disque doit être partitionné. Dans notre cas, nous avons un seul disque dur donc validez.
-
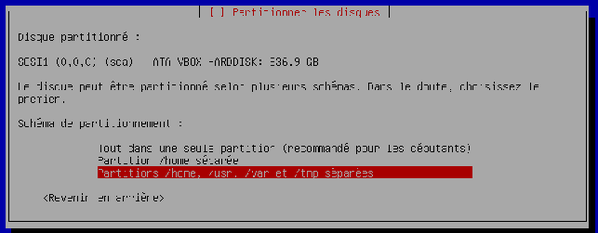
Choisissez « Partitions /home, /usr, /var et tmp séparées » comme schéma de partitionnement. Validez.
-
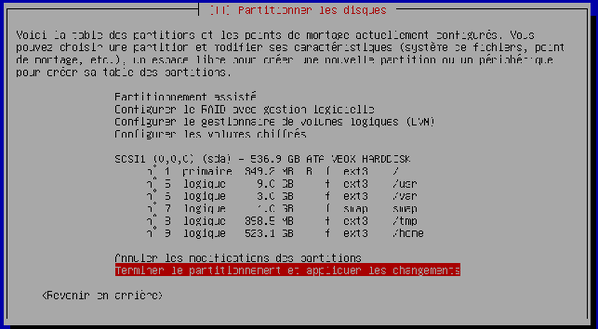
L'assistant vous propose une organisation du disque dur. Confirmez-la en choisissant « Terminer le partitionnement et appliquer les changements ». Validez.
-
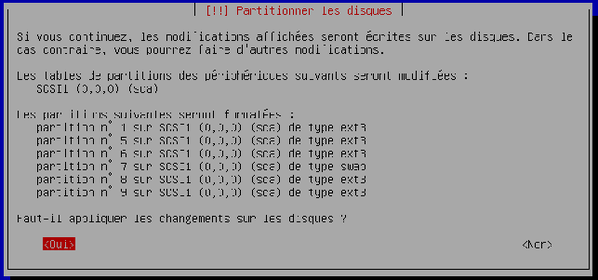
L'assistant vous demande de confirmer l'organisation du disque avant son application. Choisissez « Oui » et validez.
-
Le système formate votre disque dur et installe les composants de base. Bien que vous n'ayez rien à faire, ne partez pas trop loin, car l'assistant va bientôt avoir d'autres questions auxquelles vous devrez répondre.
-
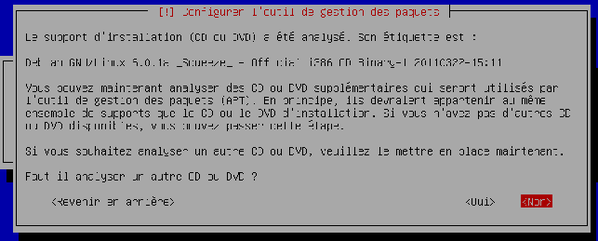
L'assistant vous demande s'il doit analyser un CD/DVD supplémentaire afin de prendre en compte des logiciels supplémentaires. Nous n'en avons pas besoin donc validez le choix « Non ».
-
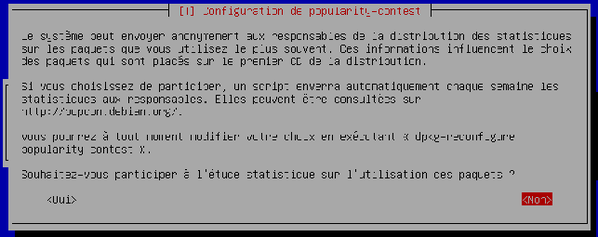
L'assistant vous demande si vous souhaitez participer, de manière anonyme aux statistiques d'utilisation des logiciels. Laissez le choix par défaut, « Non », et validez.
-
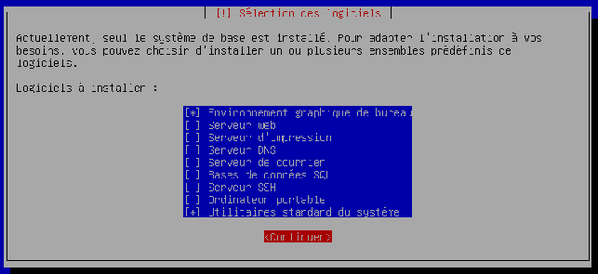
Le système nous demande ensuite les logiciels supplémentaires à installer. Par défaut, « Environnement graphique de bureau » et « Utilitaires standard du système » sont cochés. Nous ne voulons rien de plus. Appuyez sur la touche tabulation de votre clavier et validez.
-
Le système installe les logiciels supplémentaires sans vous questionner. Patientez.
-
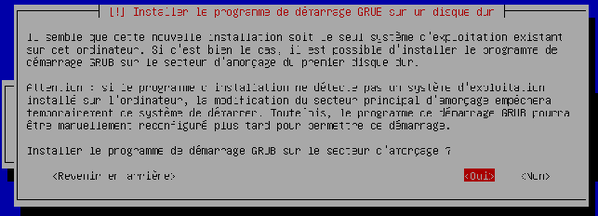
L'assistant vous demande si vous voulez installer le programme de démarrage (= bootloader) sur le secteur d’amorçage de votre disque dur. Choisissez « Oui » et validez.
-
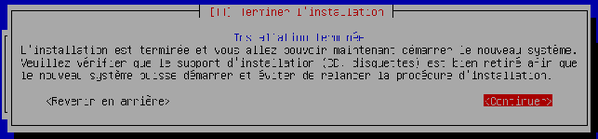
L'assistant vous informe ensuite que l'installation est finie. Retirez le CD du lecteur et validez.
Configuration du système d'exploitation GNU/Linux Debian Squeeze
Nous allons :
- Configurer les cartes réseau
- Configurer les deux logiciels (apt-get/wget) servant à l'installation de Clonezilla Server Édition et à la mise à jour du système pour qu'ils utilisent le serveur mandataire.
- Configurer le logiciel de gestion des autres logiciels (apt-get) afin de permettre l'installation de Clonezilla Server Édition.
- Configurer le système pour que le clavier numérique soit automatiquement activé dès le démarrage.
Note : je suppose ici que vous suivez le tutoriel et que donc votre dernière action sur la machine est le redemarrage de la machine suite à la fin de l'installation de GNU/Linux Debian.
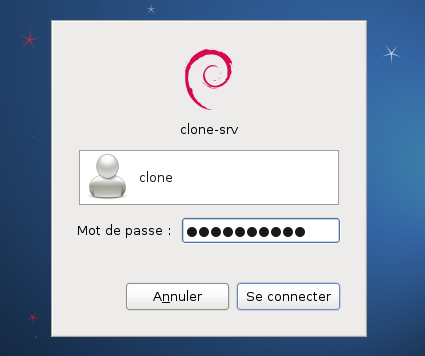
Au redémarrage de la machine, vous arrivez sur l’écran de connexion. Connectez-vous. Attention : lors de la saisie du mot de passe, le pavé numérique n'est pas activé sur certaines machines.
-
Ouvrez un terminal (= une console) en utilisant le menu Applications -> Accessoires -> Terminal. C'est cette manipulation qu'il faudra réaliser de nouveau si vous fermez le terminal ou si nous vous demandons d'ouvrir un terminal.
-
Obtenez les droits du super-utilisateur. Pour cela, tapez la commande :
(le tiret n'est pas une coquille) et validez. Saisissez le mot de passe du super-utilisateur et validez. Attention : même si rien n'apparaît à l'écran, la saisie du mot de passe est prise en compte par le système.

-
Tapez la commande
gedit /etc/network/interfaces
|
et validez. C'est cette opération qu'il faudra réaliser lorsque nous vous demanderons de taper une commande.

-
L’éditeur de texte gedit s'ouvre en chargeant le fichier /etc/network/interfaces. Ajoutez les lignes manquantes : de
jusqu'à
Il convient bien evidement d'adapter cet exemple à votre plan d'adressage
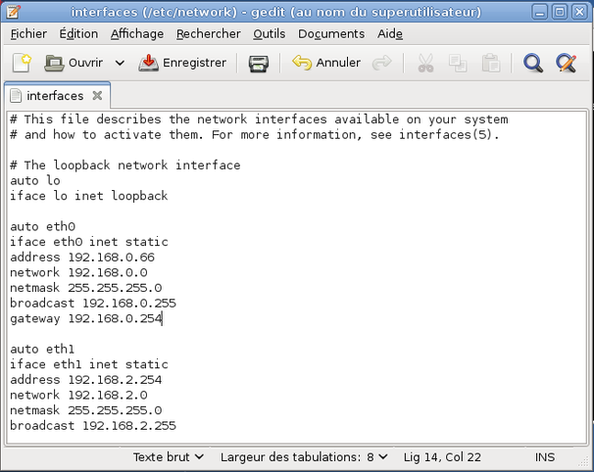
-
Enregistrez vos modifications et fermez l'éditeur.
-
Vous revenez automatiquement sur le terminal. Tapez la commande
service networking restart
|
afin que le système affecte les adresses IP aux cartes réseau.

-
Enfin, pour parfaire l'installation, il faut indiquer l'adresse IP du résolveur DNS dans le fichier /etc/resolv.conf. Cela peut se faire, de manière simple, en tapant la commande :
echo "nameserver 192.168.0.2" > /etc/resolv.conf
|

Note : si vous n'avez pas de serveur mandataire, ces étapes sont inutiles.
-
Tapez la commande :
Un fichier vide s'ouvre dans l'éditeur de texte gedit. Tapez le contenu présent sur la capture d'écran, enregistrez le fichier et quittez l'éditeur.
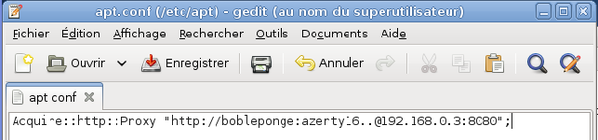
-
Tapez la commande :
Recherchez, dans le fichier, les lignes entourées en rouge dans la capture d'écran ci-dessous puis modifiez-les afin qu'elles correspondent à celles présentes dans la capture d'écran ci-dessous. Enregistrez vos modifications et quittez l'éditeur.
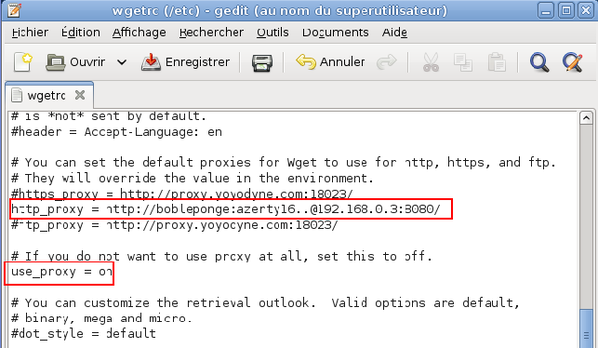
-
Tapez la commande :
gedit /etc/apt/sources.list
|
Effacez le contenu du fichier et remplacez-le par celui présent dans la capture d'écran ci-dessous. Vous pouvez ignorer les lignes de commentaires, c'est-à-dire les lignes commençant par le symbole « # ». Enregistrez vos modifications et quittez l'éditeur.
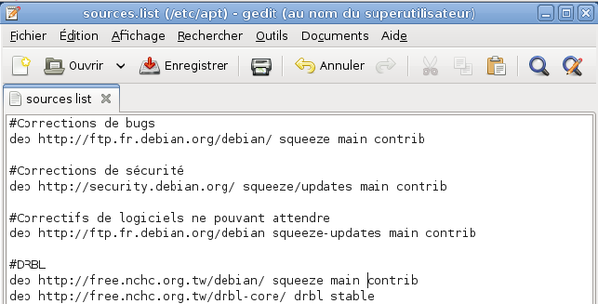
-
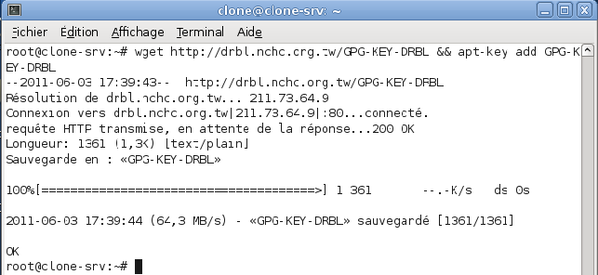
Tapez la commande :
wget http://drbl.nchc.org.tw/GPG-KEY-DRBL && apt-key add GPG-KEY-DRBL
|
Vous devez obtenir un résultat similaire à la capture d'écran ci-dessous.
Configuration du système afin que le pavé numérique soit automatiquement activé au démarrage
Note : cette étape est facultative si votre pavé numérique est automatiquement activé au démarrage.
-
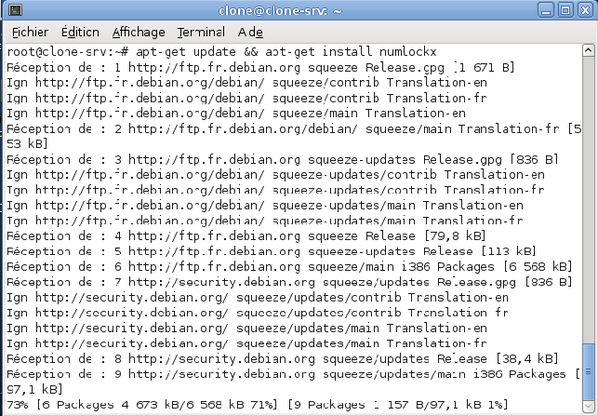
Il est nécessaire d'installer le logiciel numlockx. Cela se fait à l'aide de la commande :
apt-get update && apt-get install numlockx
|
-
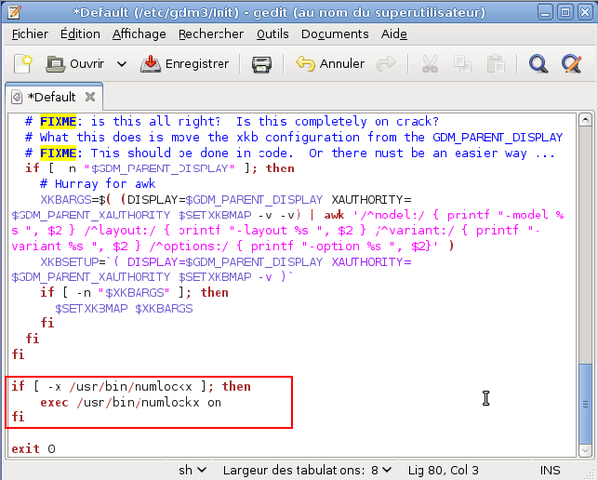
Dans un deuxième temps, il est nécessaire de modifier un fichier de configuration. Tapez la commande :
gedit /etc/gdm3/Init/Default
|
À la fin du fichier, avant la ligne « exit 0 », tapez le paragraphe entouré en rouge dans la capture d'écran ci-dessous. Enregistrez le fichier et fermez l'éditeur.
Installation de Clonezilla Server Édition
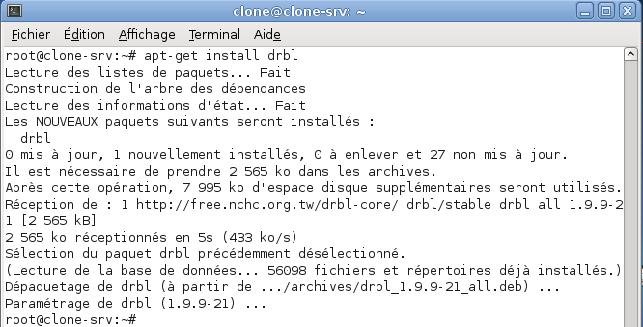
L'installation se résume à taper la commande suivante :
Configuration de Clonezilla Server Édition
La configuration de Clonezilla Server Édition se fait en deux étapes. D'abord, il faut configurer le serveur. Ensuite, il faut configurer l'environnement des clients.
Configuration du serveur
La configuration du serveur peut s'effectuer de deux manières : en tapant une seule commande ou en répondant à des questions. Nous avons choisi de taper une seule commande. Néanmoins, nous vous expliquerons les différents paramètres qu'elle comprend afin que vous puissiez faire, si vous le souhaitez, l’installation en répondant à des questions. De plus, les paramètres sont mis dans l’ordre des questions afin que vous vous y retrouviez.
Dans un terminal, il faut taper la commande :
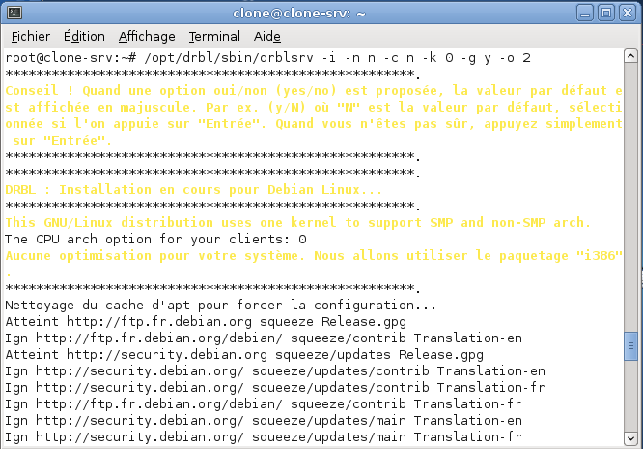
/opt/drbl/sbin/drblsrv -i -n n -c n -k 0 -g y -o 2
|
Signification :
- -n n : ne pas télécharger les images disque des distributions GNU/Linux les plus utilisées. Nous n'en avons pas besoin pour utiliser Clonezilla.
- -c n : ne pas utiliser la sortie console sur les clients.
- -k 0 : les clients utilisent une architecture CPU i386/i486. Ne changez pas ce paramètre, car il permet d'être compatible avec le plus large matériel possible (oui, j'ai eu du matériel entre les mains qui n'est pas compatible i686 durant la mise en place de ce serveur de clonage).
- -g y : mettre à jour le système (équivalent de apt-get dist-update).
- -o 2 : on utilise toujours le noyau Linux provenant du dépôt, pas celui de la machine local.
La configuration se fait de manière automatique. Il ne vous reste plus qu'à attendre le message de fin « Fait ! ».
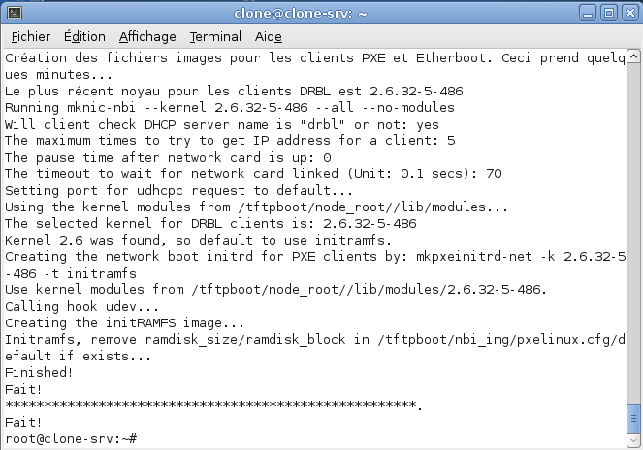
Configuration de l'environnement des clients
Cette fois-ci, l'installation se fait obligatoirement en répondant à des questions.
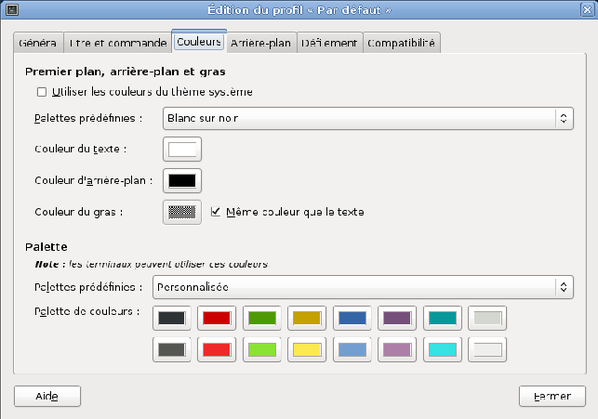
Avant de procéder à cette étape, nous allons changer la couleur du texte et celle de l'arrière-plan de notre terminal. Nous faisons cela car le script d'installation écrit en jaune dans le terminal, ce qui rend le texte illisible.
Pour faire cela, il suffit d'aller dans le menu Édition ? Préférences du profil. En se rendant dans l'onglet « Couleurs », il est possible de changer la couleur du texte et celle de l'arrière-plan en décochant la case « Utiliser les couleurs du thème système ».
Nous pouvons maintenant configurer l’environnement des clients grâce à la commande :
/opt/drbl/sbin/drblpush -i
|
-
L'assistant vous demande de saisir le nom de domaine DNS. Laissez celui qui est proposé en validant.
-
Même réponse concernant le nom de domaine NIS/YP.

-
Même réponse concernant le préfixe du nom des clients.
-
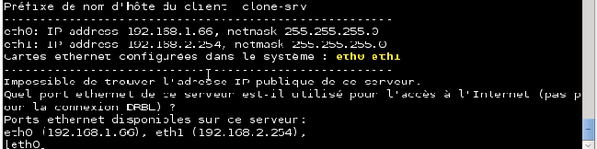
L'assistant vous demande ensuite quelle carte réseau permet d'accéder à internet. Dans notre cas, il s'agit de la carte « eth0 ». Tapez donc « eth0 » et validez.
-
L'assistant vous demande si vous souhaitez enregistrer les adresses MAC des clients. Comme nos clients sont temporaires, cette opération serait fastidieuse puisqu'il faut l'effectuer pour chaque nouveau client. Nous refusons donc en tapant « n » et en validant.
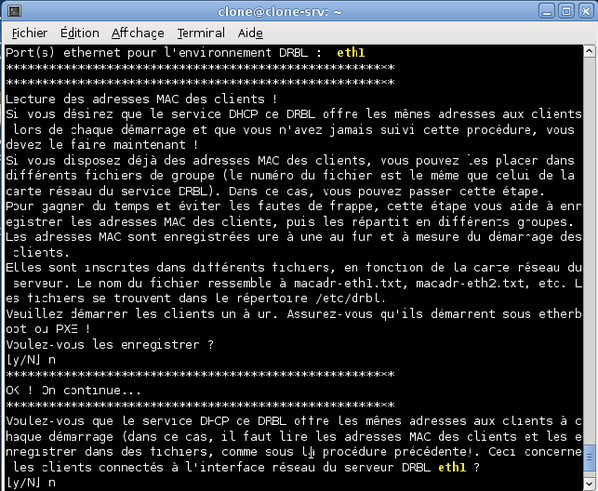
-
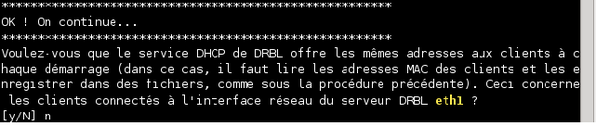
Le script nous demande si nous souhaitons réserver les mêmes adresses IP à nos machines clientes. Ceci se fait en enregistrant leurs adresses MAC. Néanmoins, pour la raison évoquée à la question précédente, nous refusons en tapant « n » et en validant.
-
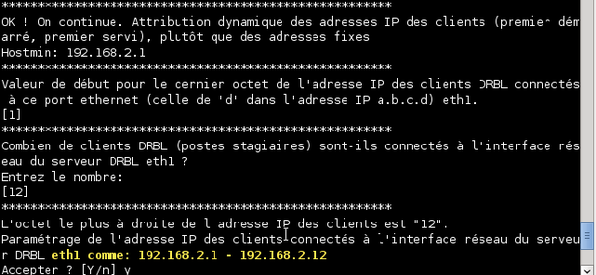
On vous demande ensuite, dans cet ordre, l'adresse IP à attribuer à la première machine qui demandera une adresse, puis le nombre total de machines. Laissez les choix proposés, à savoir : 12 machines dont les IP iront de 192.168.2.1 à 192.168.2.12 inclues. Le système vous demande ensuite si vous acceptez ces choix. Tapez « y » pour confirmer et validez.
-
Le système vous présente un schéma du réseau ainsi constitué et vous demande de confirmer. Validez.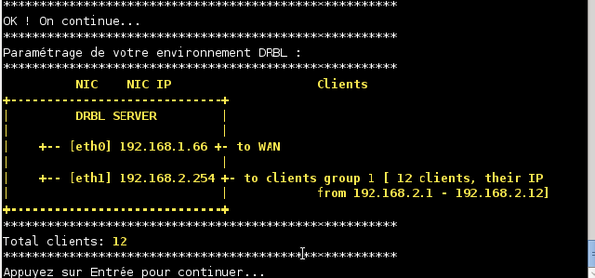
-
Le système vous demande ensuite de choisir le mode de démarrage des clients. Choisissez l'option « Mode DRBL SSI » en tapant « 1 » et en validant.
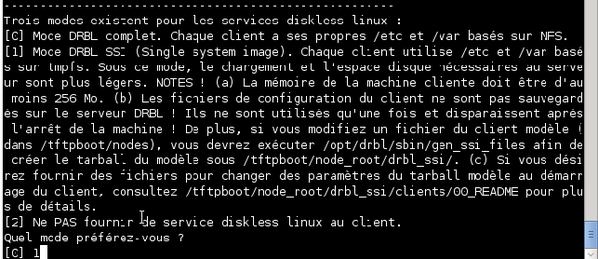
-
L'assistant vous demande ensuite le mode d’exécution de Clonezilla Server. Choisissez « Mode Clonezilla Box » en tapant « 1 » et en validant.
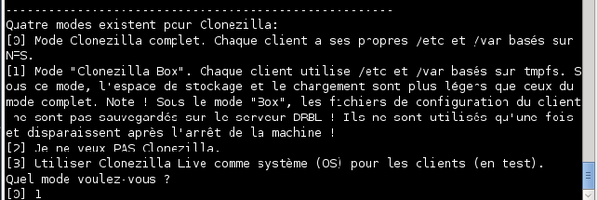
-
Le système vous demande dans quel répertoire vous souhaitez conserver les images disque réalisées. Laissez le choix par défaut (/home/partimag) et validez. Évidement, vous pouvez choisir un autre dossier (ex. : /home/clone ou bien /dev/null ;)) car le script de sauvegarde/restauration sera lancé en root et aura donc les droits de lecture/écriture dans toute l'arborescence.

-
Le système vous demande s'il doit utiliser les partitions swap des clients. Infirmez en tapant « n » et en validant.
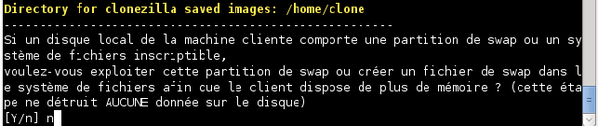
-
L'assistant vous demande si les clients doivent utiliser un menu graphique ou textuel. Choisissez un menu textuel en tapant « 2 » et en validant.

-
Les deux prochaines questions concernent des mots de passe qui peuvent être mis lors du démarrage des clients. Pour les deux, répondez par la négative en tapant « n » et en validant.
-
Le système vous demande si vous souhaitez définir le prompt de démarrage des clients. Refusez en tapant « n » et en validant.

-
Même réponse concernant l'utilisation d'un arrière-plan graphique dans le menu de démarrage.

-
Même réponse concernant l’accès au son, au lecteur CD, etc. sur les clients.
-
Répondez toujours négativement à la question concernant la création d'alias.

-
Refusez l'utilisation des clients DRBL en mode terminal en tapant « n » et en validant.
-
Le système vous demande ensuite si le serveur doit faire office de passerelle vers internet. Répondez « n » et validez.

-
Validez ensuite la demande de confirmation.
-
Le système vous demande encore une fois une confirmation avant de mettre en place la configuration. Tapez « y » et validez.
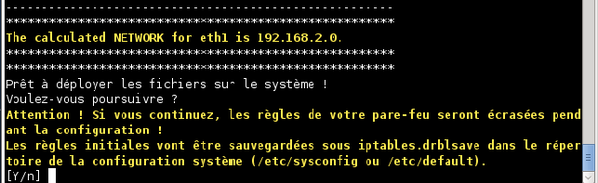
-
Attendez le message indiquant la fin de la procédure de configuration.
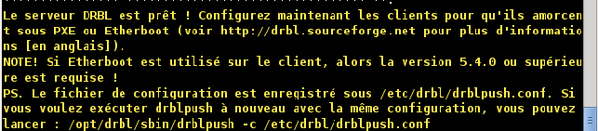
Dans un premier temps, nous allons créer un raccourci vers Clonezilla Server Édition. Dans un deuxième temps, nous créerons un script permettant de mettre facilement à jour tout le système ainsi qu'un raccourci vers ce script.
ATTENTION : Si vous ne souhaitez pas créer ces raccourcis, sachez que la commande pour lancer Clonezilla Server Édition est :
Par ailleurs, les commandes pour mettre à jour le système sont les suivantes (en utilisant le compte super-utilisateur évidemment) :
apt-get update && apt-get dist-upgrade
/opt/drbl/sbin/drblsrv -i -n n -c n -k 0 – g y -o 2
/opt/drbl/sbin/drblpush -i -c /etc/drbl/drblpush.conf
reboot
|
La première commande met à jour la liste des logiciels disponibles et, en cas de succès, met à jour tout le système. La deuxième commande reconfigure le serveur DRBL. La troisième commande reconfigure l’environnement des clients. La dernière commande permet de redémarrer le serveur afin de s'assurer qu'on utilisera bien les derniers composants (notamment le dernier noyau Linux).
Dans le reste de ce tutoriel, je considérerai que vous avez créer les raccourcis. Si ce n'est pas le cas, il faudra adapter mes écrits à votre installation.
Création d'un raccourci vers Clonezilla Server Édition
-
Il est nécessaire d'installer un logiciel supplémentaire qui permet de lancer des commandes comme si l'utilisateur la lançant était le super-utilisateur. Il s'agit du logiciel sudo. Pour l'installer, il faut taper la commande :
-
Tapez la commande :
Cela a pour effet d'ajouter le compte utilisateur « clone » au groupe « sudo » car uniquement les membres de ce groupe peuvent obtenir les privilèges du super-utilisateur avec sudo. Il est nécessaire de fermer la session utilisateur « clone » pour que les modifications soient prises en compte.
-
Tapez la commande :
gedit /usr/share/applications/clonezilla.desktop
|
-
Un fichier vide s'ouvre alors dans l'éditeur de texte. Remplissez-le avec les lignes contenues dans la capture d'écran ci-dessous. Enregistrez vos modifications et quittez l'éditeur.
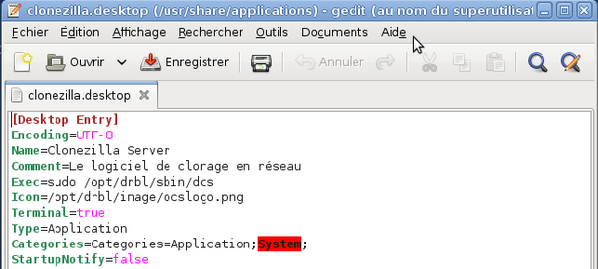
-
Un raccourci vers Clonezilla Server est disponible dans le menu Applications ? Outils système. Vous pouvez faire glisser ce raccourci sur le bureau afin d'avoir également un raccourci sur le bureau.
Création d'un script de mise à jour de tout le système
-
Tapez la commande :
-
Un fichier vide s'ouvre alors dans l'éditeur de texte. Remplissez-le avec les lignes contenues dans la capture d'écran ci-dessous. Enregistrez vos modifications et quittez l'éditeur.
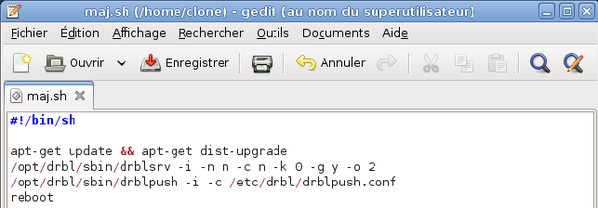
Création d'un raccourci vers le script de mise à jour
-
Tapez la commande :
gedit /usr/share/applications/maj.desktop
|
-
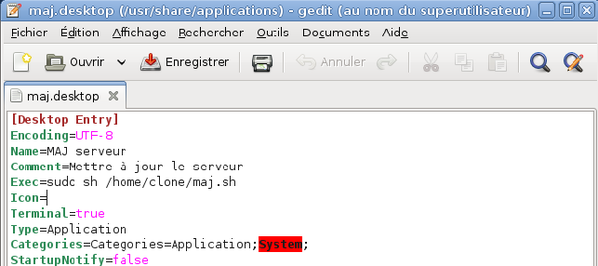
Un fichier vide s'ouvre alors dans l'éditeur de texte. Remplissez-le avec les lignes contenues dans la capture d'écran ci-dessous. Enregistrez vos modifications et quittez l'éditeur.
-
Un raccourci vers le script de mise à jour est disponible dans le menu Applications ? Outils système. Vous pouvez faire glisser ce raccourci sur le bureau afin d'avoir également un raccourci sur le bureau.
Utilisation de Clonezilla Server Édition
L'utilisation se fait en deux temps. Dans un premier temps, on sauvegarde le disque dur de la machine modèle vers une image disque. Dans un deuxième temps, on restaure l'image disque sur le reste des machines entrantes dans le parc.
Sauvegarde de la machine modèle
-
Cliquez sur l'icône « Clonezilla Server » présente sur le bureau.
-
Le mot de passe du super-utilisateur vous est demandé. Saisissez-le. Attention : rien n'apparaît à l'écran mais votre saisie est tout de même prise en compte.

-
L'assistant démarre et vous demande si la manipulation concerne une partie du parc ou la totalité. L'option « une partie des clients par IP ou adresse MAC » ne fonctionnera pas car nous n'avons pas fixé les adresses IP/MAC puisque nos clients sont temporaires. Donc, validez le choix « Sélectionner tous les clients ».
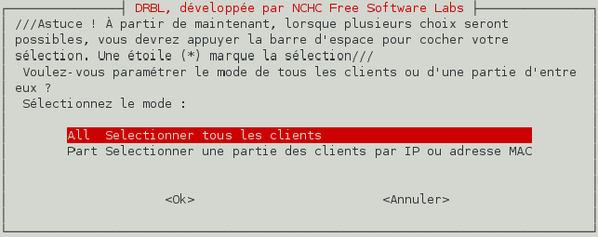
-
Nous voulons démarrer Clonezilla donc choisissez « Démarrage mode Clonezilla » et validez.
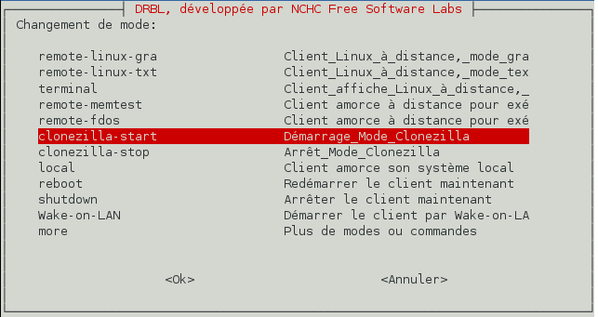
-
Clonezilla nous demande quel mode nous voulons. Le « mode expert » permet de définir des paramètres avancés (ex. : compression plus ou moins efficace/gourmande). Néanmoins, les options par défaut sont suffisantes donc validez le choix « mode débutant ».
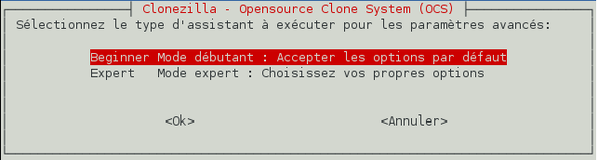
-
Nous voulons sauvegarder l'intégralité d'un disque dur donc choisissez l'option « Sauvegarde totale du disque » et validez.
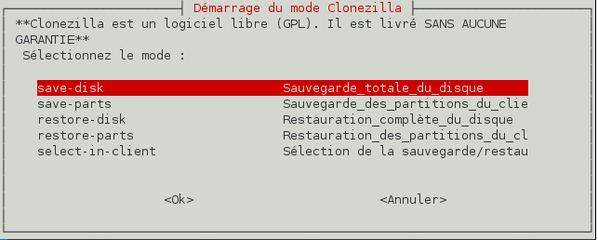
-
Nous voulons choisir le nom de l'image disque qui sera créée maintenant afin de ne pas avoir à agir sur le client. Validez donc le choix « Entrer maintenant le nom de l'image ».
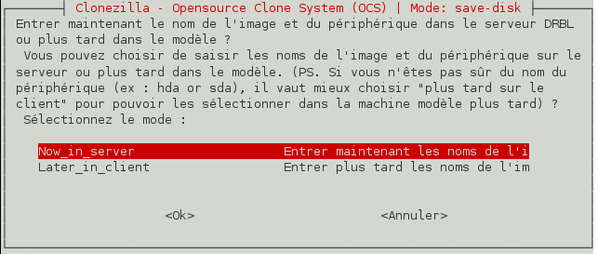
-
Choisissez un nom pour l'image disque, tapez-le et validez.
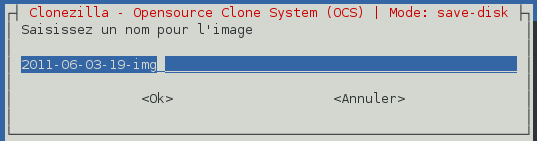
-
Il faut à présent choisir le ou les disque(s) dur(s) à sauvegarder. Pas d'hésitation ici : tous nos disques ont la notation « sda » sous GNU/Linux. Dans notre cas, nous voulons sauvegarder la partition Windows et la partition de données (qui est vide) qui sont toutes deux contenues sur le premier disque. Nous allons donc taper « sda » et valider. Néanmoins, si la machine comporte 2 disques, tapez « sda sdb » pour sauvegarder les deux disques. Pour sauvegarder uniquement le deuxième disque, tapez « sdb ». Etc. .
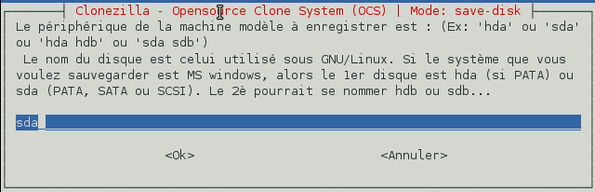
-
Nous souhaitons vérifier que l'image disque sauvegardée a été correctement réalisée donc validez l'option proposée « Oui, vérifier l'image sauvegardée ».
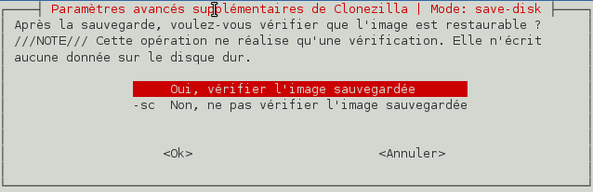
-
À la fin du processus de sauvegarde, nous souhaitons éteindre la machine cliente. Choisissez l'option « Arrêter le client en fin de clonage » et validez.
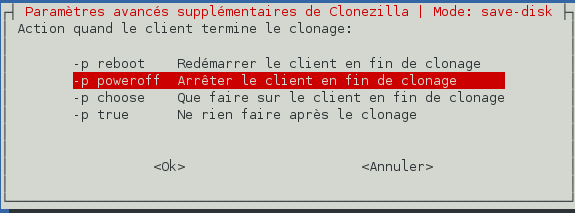
-
Nous ne souhaitons pas couper l'image disque en plusieurs morceaux afin de pouvoir la répartir sur plusieurs médiums différents. Il faut donc entrer une grande valeur. Rajoutez quelques zéros et validez.
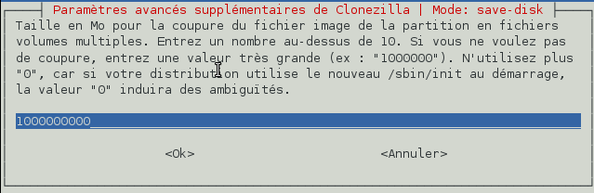
-
Clonezilla vous demande une confirmation. Validez.
-
Le terminal va se fermer.
Vous pouvez démarrer la machine à cloner après l'avoir raccordée au réseau de clonage et avoir vérifié que son BIOS autorise le démarrage depuis le réseau.
Aucune indication n'apparaît sur le serveur pour annoncer le début et/ou la fin du processus. Néanmoins, en observant le commutateur réseau, vous observerez une période avec un fort trafic réseau puis une période calme. Vous verrez également une forte période d'écriture sur le disque dur du serveur, suivie d'une période calme indiquant également le début et la fin de la sauvegarde. De plus, la machine cliente s’éteindra en fin de sauvegarde. Néanmoins, rien ne vous empêche de brancher un écran sur la machine cliente avant de la démarrer afin de surveiller le déroulement des opérations.
Note : si vous n'utilisez pas les raccourcis et que vous lancez Clonezilla depuis la ligne de commande, alors vous verrez des messages s'afficher dans la console et vous indiquant la connexion de la machine au serveur ainsi que la fin de la sauvegarde.
Si vous branchez un écran sur la machine cliente, voici ce que vous verrez :
La machine cliente obtient une adresse IP via DHCP puis charge un menu de démarrage depuis le serveur via le réseau. Le menu s'affiche ensuite et le chargement d'un système GNU/Linux minimal, lui aussi récupéré sur le serveur, s'effectue.
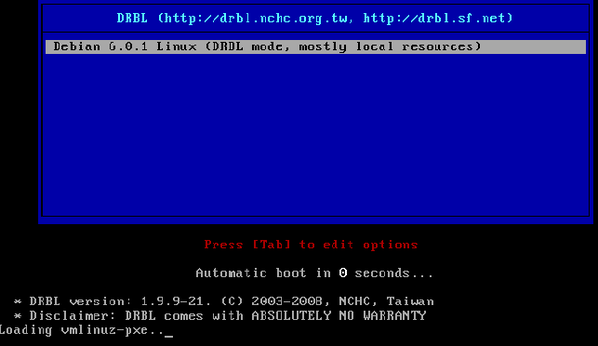
Ensuite, le processus de sauvegarde s'effectue.
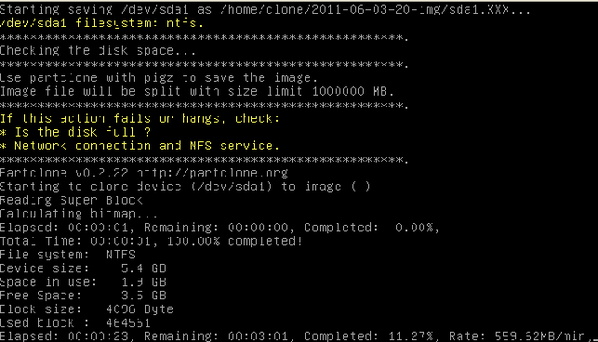
-
À la fin de la sauvegarde, il convient de faire le ménage dans les fichiers créés sur le serveur pour l'opération. Pour cela, cliquez sur l'icône Clonezilla Server sur le bureau. Le système vous demande le mot de passe du super-utilisateur. Tapez-le et validez.
-
Confirmez, là encore, que l'opération concerne toutes les machines en validant le choix proposé (« Sélectionner tous les clients »).
-
Choisissez ensuite l'option « Arrêt mode Clonezilla » dans le menu et validez.
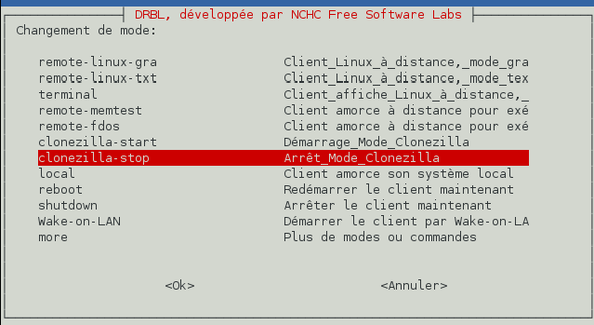
-
Les opérations de nettoyage sont effectuées et le terminal se ferme.
La création de l'image disque de la machine modèle est finie.
Restaurer l'image de la machine modèle sur les autres machines
-
Cliquez sur l'icône « Clonezilla Server » présente sur le bureau afin de le lancer.
-
Le mot de passe du super-utilisateur vous est demandé. Saisissez-le. Attention : rien n'apparaît à l'écran mais votre saisie est tout de même prise en compte.
-
L'assistant démarre et vous demande si la manipulation concerne une partie du parc ou la totalité. L'option « une partie des clients par IP ou adresse MAC » ne fonctionnera pas car nous n'avons pas fixé les adresses IP/MAC puisque nos clients sont temporaires. Donc, validez le choix « Sélectionner tous les clients ».
-
Nous voulons démarrer Clonezilla donc choisissez « Démarrage mode Clonezilla » et validez.
-
Clonezilla nous demande quel mode nous voulons. Le « mode expert » permet de définir des paramètres avancés (ex. : compression plus ou moins efficace/gourmande). Néanmoins, les options par défaut sont suffisantes donc validez le choix « mode débutant ».
-
Nous voulons restaurer l'intégralité du disque dur donc choisissez l'option « Restauration complète du disque » et validez.
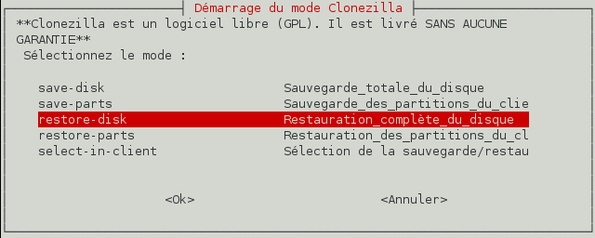
-
À la fin du processus de sauvegarde, nous souhaitons éteindre la machine cliente. Choisissez l'option « Arrêter le client en fin de clonage » et validez.
-
Clonezilla Server vous demande ensuite quelle image disque doit être restaurée. Choisissez la bonne image dans la liste et validez.
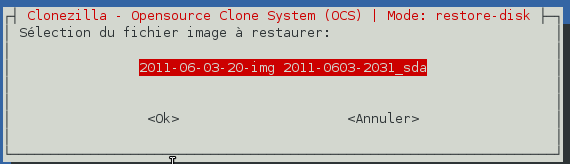
-
Choisissez ensuite les disques durs à restaurer. Dans notre cas, il n'y a qu'un disque sauvegardé dans l'image mais dans le cas de plusieurs disques sauvegardés dans une même image, cette option s'avère utile pour ne pas restaurer tous les disques.
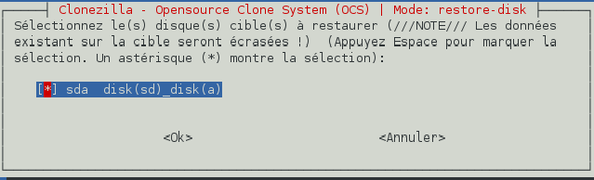
-
Il faut à présent sélectionner le mode de transmission réseau de l'image disque. « Unicast » consiste à envoyer l'information autant de fois qu'il y a de machines à restaurer. Ceci implique une forte charge pour le serveur et pour le réseau. « Broadcast » consiste à envoyer une seule fois l'information à l'ensemble des machines présentes sur le réseau. Libre ensuite aux machines de traiter l'information transmise. « Multicast » permet d'envoyer une seule fois l'information à un groupe de machines s'étant enregistrées dans le groupe de diffusion. Il s'agit d'une optimisation du mode broadcast puisque seules les machines ayant fait la demande reçoivent l'information. Nous allons donc utiliser le mode « multicast ». Validez cette option.
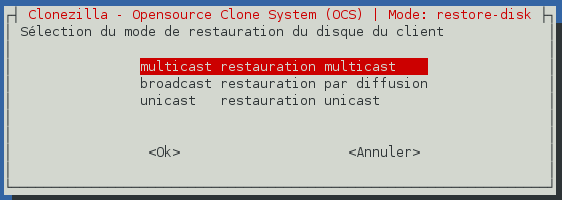
-
Nous devons maintenant définir la période de temps durant laquelle on attend les clients. « Clients to wait » permet de spécifier le nombre de machines qui doivent être attendues avant le lancement de la procédure. « Time to wait » permet de définir le délai d'attente des machines clientes. Ce délai commence à partir de l'enregistrement de la première machine cliente auprès du serveur. Enfin, « Clients+time to wait » est la réunion des deux modes précédents. Afin de nous assurer qu'aucun client ne sera ignoré si celui-ci ne démarre pas sur le réseau, choisissez l'option « clients to wait » et validez.
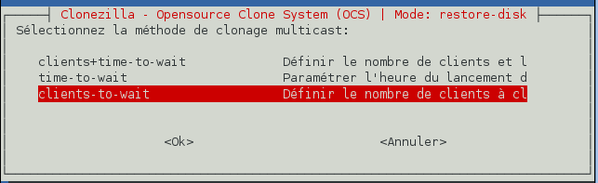
-
Indiquez le nombre de clients à attendre et validez.
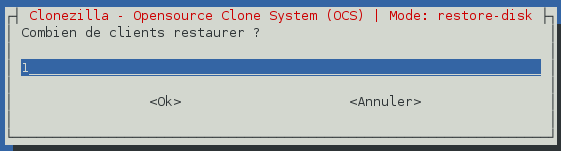
-
Clonezilla vous demande une confirmation. Validez.
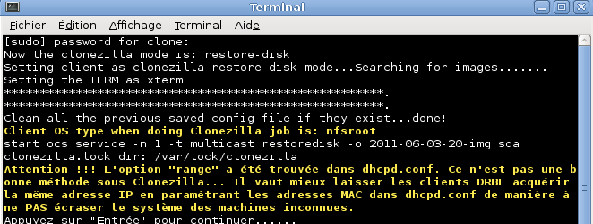
-
Clonezilla vous demande de confirmer que le matériel réseau est prêt pour la restauration multicast. Validez.
-
Le terminal va se fermer.
Vous pouvez démarrer les machines à restaurer après les avoir raccordées au réseau de clonage et avoir vérifié que leur BIOS autorise le démarrage depuis le réseau.
Aucune indication n'apparaît sur le serveur pour annoncer le début et/ou la fin du processus. Néanmoins, en observant le commutateur réseau, vous observerez une période avec un fort trafic réseau puis une période calme. Vous verrez également une forte période de lecture sur le disque dur du serveur, suivie d'une période calme indiquant également le début et la fin de la sauvegarde. De plus, les machines clientes s’éteindront en fin de sauvegarde. Néanmoins, rien ne vous empêche de brancher un écran sur une des machines clientes avant de la démarrer afin de surveiller le déroulement des opérations.
Note : si vous n'utilisez pas les raccourcis et que vous lancez Clonezilla depuis la ligne de commande, alors vous verrez des messages s'afficher dans la console et vous indiquant les machines qui se connectent au serveur ainsi que la fin de la restauration.
Si vous branchez un écran sur une des machines clientes, voici ce que vous verrez :
La machine cliente obtient une adresse IP via DHCP puis charge un menu de démarrage depuis le serveur via le réseau. Le menu s'affiche ensuite et le chargement d'un système GNU/Linux minimal, lui aussi récupéré sur le serveur, s'effectue.
Ensuite, le processus de restauration de l'image va commencer.
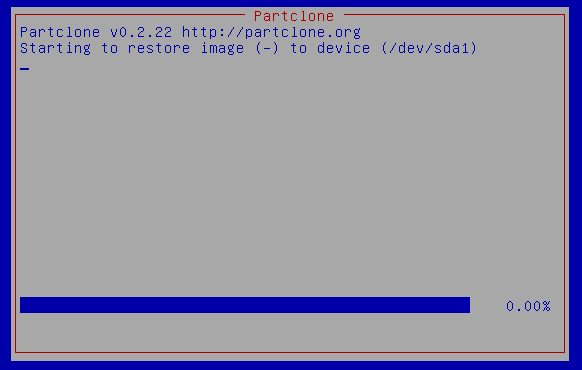
-
À la fin de la restauration, il convient de faire le ménage dans les fichiers créés sur le serveur pour l'opération. Pour cela, cliquez sur l'icône Clonezilla Server sur le bureau. Le système vous demande le mot de passe du super-utilisateur. Tapez-le et validez.
-
Confirmez, là encore, que l'opération concerne toutes les machines en validant le choix proposé (« Sélectionner tous les clients »).
-
Choisissez ensuite l'option « Arrêt mode Clonezilla » dans le menu et validez.
-
Les opérations de nettoyage sont effectuées et le terminal se ferme.
L'image a donc été restaurée sur toutes les machines.
Mise à jour du serveur
Interêt de la mise à jour
Il est important de mettre à jour ce serveur de clonage de manière régulière. D'une part afin de garantir une correction des bogues découverts et donc une plus grande stabilité du serveur. D'autre part afin de pouvoir supporter le matériel récent, et donc, de ce fait, les machines clientes récentes. En effet, les mises à jour, notamment celles du noyau Linux amènent un support matériel élargi.
IMPORTANT : nous n'avons pas planifié de mises à jour automatiques du système afin d'éviter que des clients ne démarrent plus du jour au lendemain sans raison apparente et afin de ne pas gêner l'utilisation du serveur. En effet, puisqu'il n'est pas allumé en permanence, la mise à jour se ferait au démarrage du serveur. Or, si l'on allume le serveur, c'est qu'on en a besoin maintenant.
Si vous avez suivi la procédure pour créer un script de mise à jour ainsi qu'un raccourci vers celui-ci dans le menu et sur le bureau, vous avez juste à cliquer sur l'un de ces raccourcis pour mettre à jour l'intégralité du système.
Si vous n'avez pas suivi la procédure, vous devez mettre à jour le système en tapant les commandes suivantes (leur signification est expliquée dans la partie concernant la création des raccourcis :
apt-get update && apt-get dist-upgrade
/opt/drbl/sbin/drblsrv -i -n n -c n -k 0 – g y -o
/opt/drbl/sbin/drblpush -i -c /etc/drbl/drblpush.conf
reboot
|
Dans tous les cas, si le serveur vous demande une confirmation pour effectuer la mise à jour, du type « Appuyez sur Entrée pour continuer » ou équivalent, validez.
Dépannage rapide : Les machines clientes ne démarrent pas !
Problème : Une ou plusieurs machines clientes démarrent depuis le réseau, mais la sauvegarde ne se fait pas (il n'y a pas de trafic ni d’écriture sur le disque dur du serveur). Vous avez branché un écran sur une des machines clientes et vous avez constaté que le menu s'affiche, que le système commence à se charger, mais que le chargement plante en affichant des lignes incompréhensibles.
Solution : Un composant matériel essentiel de la machine n'est pas pris en charge par le système GNU/Linux minimal qui est chargé sur les machines clientes par le serveur.
La seule solution est de tenter une mise à jour du serveur. Si le composant a été pris en charge dans les versions récentes des logiciels, alors les machines clientes pourront être clonées. Pour mettre à jour l'intégralité du système, veuillez vous reporter à la section « Mise à jour de la solution ».
Si le problème n'est pas résolu après une tentative de mise à jour, considérez que vous ne pouvez pas cloner la machine avec la solution avec Clonezilla Server Édition pour le moment.
ÉDIT du 11/07/2011 à 21h45 : J'ai oublié de le préciser mais si le menu apparait sur les postes clients mais que le noyau ne s’exécute pas, alors vous avez sans doute un problème d’incompatibilité entre l'architecture CPU réelle et celle choisie lors de la configuration du serveur. Par exemple : vous avez choisi l'architecture i686 alors que vos machines clientes ont l'i586 pour architecture. Dans ce cas-là, il existe une solution : reconfigurer le serveur et l'environnement des clients en choisissant une architecture antérieure à celle choisie auparavant. J'ai rencontré ce problème et cette solution l'a résolu. Néanmoins, si cela ne fonctionne pas pour vous, même avec l'architecture i386, alors vous avez sans doute un matériel qui n'est pas supporté par le système GNU/Linux minimal qui est chargé sur les machines.
Sources documentaires
Comme d'habitude, je vous indique les sites qui m'ont aidé dans la mise en place de mon projet et dans l'écriture de ce billet.